脱氧核糖核酸
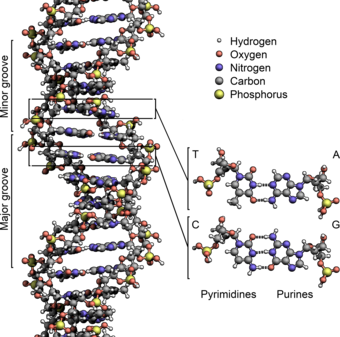
脱氧核醣核酸(DNA)的雙股螺旋结构。在该结构中的原子是按元素进行颜色编码,还有两个碱基对的详细结构示于右下角

脫氧核醣核酸雙股螺旋
脱氧核醣核酸(英语:deoxyribonucleic acid,縮寫:DNA)又稱去氧核醣核酸,是一種生物大分子,可組成遺傳指令,引導生物發育與生命機能運作。主要功能是資訊儲存,可比喻為「藍圖」或「配方」[1]。其中包含的指令,是建構細胞內其他的化合物,如蛋白質與核醣核酸所需。帶有蛋白質編碼的DNA片段稱為基因。其他的DNA序列,有些直接以本身構造發揮作用,有些則參與調控遺傳訊息的表現。
DNA是一種長鏈聚合物,組成單位稱為核苷酸,而糖類與磷酸藉由酯鍵相連,組成其長鏈骨架。每個糖單位都與四種鹼基裡的其中一種相接,這些鹼基沿著DNA長鏈所排列而成的序列,可組成遺傳密碼,是蛋白質氨基酸序列合成的依據。讀取密碼的過程稱為轉錄,是根據DNA序列複製出一段稱為RNA的核酸分子。多數RNA帶有合成蛋白質的訊息,另有一些本身就擁有特殊功能,例如核糖體RNA、小核RNA與小干擾RNA。
在細胞內,DNA能組織成染色體結構,整組染色體則統稱為基因組。染色體在細胞分裂之前會先行複製,此過程稱為DNA複製。對真核生物,如動物、植物及真菌而言,染色體是存放於細胞核內;對於原核生物而言,如細菌,則是存放在細胞質中的拟核裡。染色體上的染色質蛋白,如組織蛋白,能夠將DNA組織並壓縮,以幫助DNA與其他蛋白質進行交互作用,進而調節基因的轉錄。
目录
1 物理與化學性質
2 鹼基配對
3 正意與反意
4 超螺旋
5 各種類型的雙螺旋結構
6 四聯體結構
7 化學修飾
7.1 鹼基修飾
7.2 脱氧核醣核酸損害
8 生物機能概觀
8.1 基因組結構
8.2 轉錄與轉譯
8.3 複製
9 與蛋白質的交互作用
9.1 脱氧核醣核酸結合蛋白
9.2 脱氧核醣核酸修飾酵素
9.2.1 核酸酶與連接酶
9.2.2 拓撲異構酶與螺旋酶
9.2.3 聚合酶
10 遺傳重組
11 脱氧核醣核酸生物代謝的演化
12 技術應用
12.1 遺傳工程
12.2 法醫鑑識
12.3 歷史學與人類學
12.4 生物資訊學
12.5 脱氧核醣核酸與電腦
12.6 脱氧核醣核酸與纳米科技
13 歷史
14 参见
15 參考文獻
16 延伸閱讀
17 外部連結
物理與化學性質

脱氧核醣核酸的化學結構。
脱氧核醣核酸是一種由核苷酸重複排列組成的長链聚合物[2][3],寬度約22到24埃(2.2到2.4纳米),每一個核苷酸單位則大約長3.3埃(0.33纳米)[4]。在整個脱氧核醣核酸聚合物中,可能含有數百萬個相連的核苷酸。例如人類細胞中最大的1號染色體中,就有2億2千萬個鹼基對[5]。通常在生物體內,脱氧核醣核酸並非單一分子,而是形成兩條互相配對並緊密結合[6][7],且如藤蔓般地纏繞成雙螺旋結構的分子。每個核苷酸分子的其中一部分會相互連結,組成長链骨架;另一部分稱為鹼基,可使成對的兩條脱氧核醣核酸相互結合。所謂核苷酸,是指一個核苷加上一個或多個磷酸基團,核苷則是指一個鹼基加上一個糖類分子[8]。
脱氧核醣核酸骨架是由磷酸與醣類基團交互排列而成[9]。組成脱氧核醣核酸的糖類分子為環狀的2-脫氧核醣,屬於五碳糖的一種。磷酸基團上的兩個氧原子分別接在五碳糖的3號及5號碳原子上,形成磷酸雙酯鍵。這種兩側不對稱的共價鍵位置,使每一條脱氧核醣核酸長鏈皆具方向性。雙螺旋中的兩股核苷酸互以相反方向排列,這種排列方式稱為反平行。脱氧核醣核酸鏈上互不對稱的兩末端一邊叫做5'端,另一邊則稱3'端。脱氧核醣核酸與RNA最主要的差異之一,在於組成糖分子的不同,DNA為2-脫氧核醣,RNA則為核醣[7]。
| 項目 | DNA | RNA | 解說 |
|---|---|---|---|
| 組成主幹之糖類分子[7] | 2-去氧核糖和磷酸 | 核糖和磷酸 | |
| 骨架結構 | 规则的[10]:50双螺旋结构[11] | 单螺旋结构[11] | 即脱氧核糖核酸由两条脱氧核苷酸链构成,而核糖核酸由一条核糖核苷酸链构成。[10]:49 |
核苷酸數 | 通常上百萬 | 通常數百至數千個 | |
鹼基種類[12][11] | 腺嘌呤(A) --- 胸腺嘧啶(T) 胞嘧啶(C) --- 鳥嘌呤(G) | 腺嘌呤(A) --- 尿嘧啶(U) 胞嘧啶(C) --- 鳥嘌呤(G) | 除部分例外,DNA為胸腺嘧啶,RNA為尿嘧啶,使RNA更易被水解。 |
五碳糖種類[11] | 脫氧核醣 | 核醣 | |
五碳糖連接組成分 | 氫原子 | 羟基 | 在五碳糖的第二個碳原子上連接的組成分不同。 |
| 存在[11] | 细胞核(少量存在于线粒体、叶绿体) | 细胞质 |

DNA和RNA的组成与结构。左為RNA,右為DNA
兩股脱氧核醣核酸長鏈上的鹼基以氫鍵相互吸引,使雙螺旋形态得以維持。這些鹼基可分為兩大類,以5角及6角雜環化合物組合而成的一類稱為嘌呤;只有一個6角雜環的則稱為嘧啶[8]。組成脱氧核醣核酸的鹼基,分別是腺嘌呤(adenine,縮寫A)、胞嘧啶(cytosine,C)、鳥嘌呤(guanine,G)與胸腺嘧啶(thymine,T)。鹼基、糖類分子與磷酸三者結合之後,便成為完整的核苷酸。還有一種鹼基稱為尿嘧啶(uracil,U),此種鹼基比胸腺嘧啶少了一個位於環上的甲基,一般出現在RNA分子中,角色相當於脱氧核醣核酸裡的胸腺嘧啶。通常在脱氧核醣核酸中,它会作为胞嘧啶的分解产物,或是CpG岛中還未經甲基化的胞嘧啶突变产物。少見的例外發現於一種稱為PBS1的細菌病毒,此類病毒的脱氧核醣核酸中含有尿嘧啶[13]。在某些特定RNA分子的合成過程中,會有許多尿嘧啶在酵素的作用下失去一個甲基,因而轉變成胸腺嘧啶,這種情形大多出現於一些在構造上具有功能,或者具有酵素能力的RNA上,例如轉運RNA與核糖體RNA[14]。
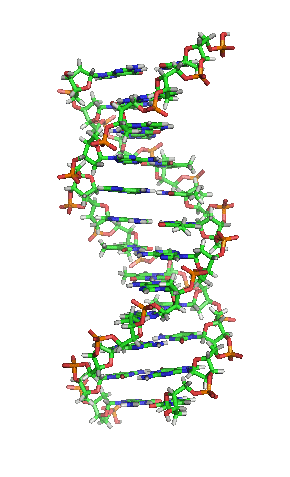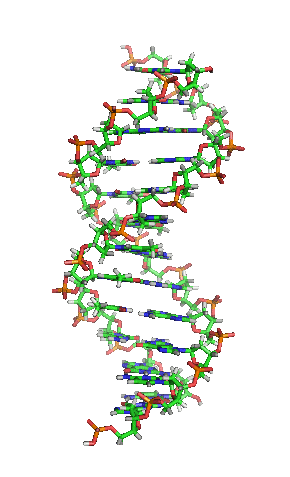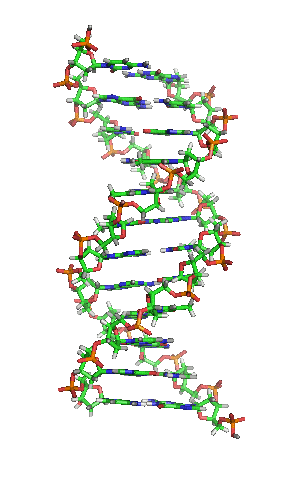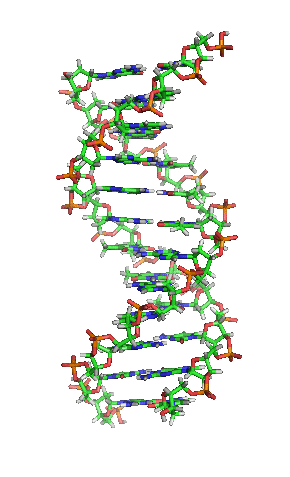
兩股脱氧核醣核酸長鏈會以右旋方式交互纏繞成雙螺旋結構,因为以磷酸联结而成的骨架位於外部,且兩股之間會留下一些空隙,因此位於螺旋內部的鹼基,即使從螺旋外側依然可見(如右方動畫)。雙螺旋的表面有兩種凹槽(或称“沟”):較大的寬22埃;較小的寬12埃[16]。由於各個鹼基靠近大凹槽的一面較容易與外界接觸,因此如轉錄因子等能夠與特定序列結合的蛋白質與鹼基接觸時,通常是作用在靠近大凹槽的一面[17]。
 |
 |
鹼基配對
一股脱氧核醣核酸上所具有的各類型含氮碱基,都只會與另一股上的一個特定類型鹼基產生鍵結。此種情形稱為互補性鹼基配對。嘌呤與嘧啶之間會形成氫鍵,在一般情况下,A只與T相連,而C只與G相連。因此排列於雙螺旋上的核苷酸,便以這種稱為鹼基對的方式相互联结。除此之外,與脱氧核醣核酸序列無關的疏水性效應,以及π重疊效應所產生的力,也是兩股脱氧核醣核酸能維持結合狀態的原因[18]。由於氫鍵比共價鍵更容易斷裂,這使雙股脱氧核醣核酸可能會因為機械力或高溫作用,而有如拉鍊一般地解開[19],这种现象被称为DNA变性。由於互補的特性,使位於雙股序列上的訊息,皆以雙倍的形式存在,這種特性對於脱氧核醣核酸複製過程來說相當重要。互補鹼基之間可逆且具專一性的交互作用,是生物脱氧核醣核酸所共同擁有的關鍵功能[2]。
兩種不同的鹼基對分別是以不同數目的氫鍵結合:A-T之間有兩條;G-C之間則有三條(見左圖)。多一條氫鍵使GC配對的穩定性高於AT配對,也因此兩股脱氧核醣核酸的結合強度,是由GC配對所佔比例,以及雙螺旋的總長度來決定。當脱氧核醣核酸雙螺旋較長且GC含量較高時,其雙股之間的結合能力較強;長度較短且AT含量較高時,結合能力則較弱[20]。雙螺旋上有某些部位必須能夠輕易解開,這些部位通常含有有較多的AT配對,例如細菌啟動子上一段含有TATAAT序列的普里布諾盒[21]。在實驗室中,若找出解開氫鍵所需的溫度,也就是所謂熔點(Tm),便能計算出兩股之間的結合強度。當脱氧核醣核酸雙螺旋上所有的鹼基配對都解開之後,溶液中的兩股脱氧核醣核酸將分裂成獨立的分子。單股脱氧核醣核酸分子並無固定的形體,但仍有某些形狀較為穩定且常見[22]。
正意與反意
一般來說,當一段脱氧核醣核酸序列之mRNA為轉譯成蛋白質的RNA序列時,稱為「正意」。而相對並互補的另一股序列,則稱為「反意」。由於RNA聚合酶的作用方式,是根據模板上的訊息來合成一段與模板互補的RNA片段,因此正意mRNA的序列實際上與脱氧核醣核酸上的正意股相同。在同一股脱氧核醣核酸上,可能同時會有屬於正意和反意的片段。此外,反意RNA在原核生物或真核生物體內皆存在,但是其功能尚未明瞭[23]。有研究認為,反意RNA可利用RNA與RNA之間的鹼基配對,來調控基因的表現[24]。
少數屬於原核生物、真核生物、質體或病毒的脱氧核醣核酸序列(後兩者較前兩者多),會由於正意股與反意股之間的差異難以區分,而產生重疊基因[25],這類脱氧核醣核酸序列具有雙重功能,一方面能以5'往3'的方向合成蛋白質,另一方面也能以相反方向合成另一個蛋白質。這種重疊現象一方面在細菌體內參與調控基因的轉錄[26],一方面則在較小的病毒基因組中,扮演增加訊息量的角色[27]。為了縮減基因組的大小,也有某些病毒以線狀或環狀的單股脱氧核醣核酸作為遺傳物質[28][29]。
超螺旋
脱氧核醣核酸链在双螺旋基础上如繩索般扭轉的現象與過程稱為DNA超螺旋。當脱氧核醣核酸處於「鬆弛」狀態時,雙螺旋的兩股通常會延着中軸,以每10.4個鹼基對旋轉一圈的方式扭轉。但如果脱氧核醣核酸受到扭轉,其兩股的纏繞方式將變得更緊或更鬆[30]。當脱氧核醣核酸扭轉方向與雙股螺旋的旋轉方向相同時,稱為正超螺旋,此時鹼基將更加緊密地結合。反之若扭轉方向與雙股螺旋相反,則稱為負超螺旋,鹼基之間的結合度會降低。自然界中大多數的脱氧核醣核酸,會因為拓撲異構酶的作用,而形成輕微的負超螺旋狀態[31]。拓撲異構酶同時也在轉錄作用或DNA複製過程中,負責紓解脱氧核醣核酸鏈所受的扭轉壓力[32]。

由左到右分別為A型、B型與Z型三種脱氧核醣核酸結構。
各種類型的雙螺旋結構
脱氧核醣核酸有多種不同的構象,其中有些構象之間在構造上的差異並不大。目前已辨識出來的構象包括:A-DNA、B-DNA、C-DNA、D-DNA[33]、E-DNA[34]、H-DNA[35]、L-DNA[33]、P-DNA[36]與Z-DNA[9][37]。不過以現有的生物系統來說,自然界中可見的只有A-DNA、B-DNA與Z-DNA。脱氧核醣核酸所具有的構象可根據脱氧核醣核酸序列、超螺旋的程度與方向、鹼基上的化學修飾,以及溶液狀態,如金屬離子與多胺濃度來分類[38]。三種主要構象中以B型為細胞中最常見的類型[39],與另兩種脱氧核醣核酸雙螺旋的差異,在於其幾何形态與尺寸。
其中A型擁有較大的寬度與右旋結構,小凹槽較淺且較寬,大凹槽則較深較窄。A型一般存在於非生理狀態的脫水樣本中,在細胞中則可能為脱氧核醣核酸與RNA混合而成的產物(類似酵素及脱氧核醣核酸的複合物)[40][41]。若一段脱氧核醣核酸上的鹼基受到一種稱為甲基化的化學修飾,將使其構型轉變成Z型。此時螺旋形式轉為左旋,與較常見的右旋B型相反[42]。某些專門與Z-脱氧核醣核酸結合的蛋白質可辨識出這種少見的結構,此外Z型脱氧核醣核酸可能參與了轉錄作用的調控[43]。
四聯體結構
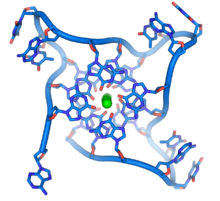
由重複排列的端粒構成的脱氧核醣核酸四聯體結構形态。脱氧核醣核酸骨架的構形與一般的螺旋結構顯著地有所不同[44]。
線狀染色體的末端有一段稱為端粒的特殊區域,由於一般參與複製脱氧核醣核酸的酵素無法作用於染色體的3'端,因此這些端粒的主要功能,是使細胞能利用一種稱為端粒酶的酵素來複製端粒[45]。如果端粒消失,那麼複製過程將使染色體長度縮小。因此這些特化的端帽能保護染色體結尾不被外切酶破壞,並阻止細胞中的DNA修復系統將其視為需修正的損毀位置[46]。在人類細胞中,端粒是由重複出現數千次TTAGGG序列的單股脱氧核醣核酸所組成[47]。
這些序列富含鳥嘌呤,可形成一種由四個鹼基重疊而成的特殊結構,使染色體末端較為穩定。四個鳥嘌呤可構成一個平面,並且重疊於其他平面之上,產生穩定的G-四聯體結構[48]。鹼基與位在四個鹼基中心的金屬離子螯合物之間,是經由氫鍵結合以穩定結構。左圖顯示由上方觀看人類端粒中的四聯體,圖中可見每四個鹼基為一組,共三層鹼基重疊而成的單股脱氧核醣核酸環狀物。在鹼基環繞的中心,可見三個螯合在一起的鉀離子[49]。也有其他類型的結構存在,例如中心的四個鹼基,除了可以是屬於單一的一股脱氧核醣核酸之外,也可能是由多條平行的脱氧核醣核酸各自貢獻一個鹼基而形成。
端粒另外還可形成一種大型環狀結構,稱為端粒環或T環(T-loop)。是由單股脱氧核醣核酸經過端粒結合蛋白的作用之後,捲曲而成的一個大迴圈[50]。在T環長鏈最前端的地方,單股的脱氧核醣核酸會附着在雙股脱氧核醣核酸之上,破壞雙螺旋脱氧核醣核酸與另一股的鹼基配對,形成一種稱為替代環或D環的三股結構[48]。
化學修飾
鹼基修飾
 |  | 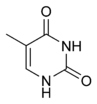 |
胞嘧啶 | 5-甲基胞嘧啶 | 胸腺嘧啶 |
基因的表現,受染色體上的染色質結構與異染色質(基因無表現或低表現)區域裡的胞嘧啶甲基化所影響。舉例而言,當胞嘧啶受到甲基化時,會轉變成5-甲基胞嘧啶,此作用對於X染色體的去活化、铭印和保护脱氧核醣核酸分子不被内切酶所切断(存在例外)而言相當重要[51]。甲基化的程度在不同生物之間有所差異,如秀麗隱桿線蟲便缺乏胞嘧啶甲基化,而在脊椎動物體內則較常出現,大約有1%的脱氧核醣核酸為5-甲基胞嘧啶[52]。5-甲基胞嘧啶容易因自然發生的脫氨作用而變成胸腺嘧啶,也因此使甲基化的胞嘧啶成為突變熱點[53],这也解释了为什么胞嘧啶和鸟嘌呤会集中出现在CpG岛里,因为那里的甲基化作用被压制,没有甲基化的胞嘧啶所产生的突变产物并非胸腺嘧啶,而是尿嘧啶。因为尿嘧啶会相对容易地被更正过来,所以CpG岛内胞嘧啶不易形成突变而会被保留下来。其他的鹼基修飾還包括細菌的腺嘌呤甲基化,以及使動質體(一種生物)的尿嘧啶轉變成「J-鹼基」的糖基化等[54][55]。

苯並芘是一種突變原,可於菸葉燃燒生成的煙中發現,圖為苯並芘與脱氧核醣核酸的加合物[56]。
脱氧核醣核酸損害
有許多不同種類的突變原可對DNA造成損害,其中包括氧化劑、烷化劑,以及高頻電磁輻射,如紫外線與X射線。不同的突變原對DNA造成不同類型的損害,舉例而言,紫外線會造成胸腺嘧啶二聚體的形成,並與相鄰的鹼基產生交叉,進而使DNA發生損害[57]。另一方面,氧化劑如自由基或過氧化氫,可造成多種不同形态的損害,尤其可對鳥苷進行鹼基修飾,並且使雙股分解[58]。根據估計,在一個人類細胞中,每天大約有500個鹼基遭受氧化損害[59][60]。在各種氧化損害當中,以雙股分解最為危險,此種損害難以修復,且可造成DNA序列的點突變、插入與刪除,以及染色體易位[61]。
許多突變原可嵌入相鄰的兩個鹼基對之間,這些嵌入劑大多是芳香性分子及平面分子,包括乙錠、道諾黴素、阿黴素與沙利竇邁。必須先使鹼基之間的空隙變大,才能使嵌入劑置入鹼基對之間,整體而言,脱氧核醣核酸會因為雙螺旋解開而扭曲變形。結構改變會使轉錄作用與脱氧核醣核酸複製過程受到抑制,進而導致毒害與突變。因此脱氧核醣核酸嵌入劑通常也是致癌物,常見的例子有二醇環氧苯並芘、吖啶、黃麴毒素與溴化乙錠等[62][63][64]。但是這些物質也因為能夠抑制脱氧核醣核酸的轉錄與複製,而可應用於化學治療中,用以抑制癌症細胞的快速生長情形[65]。
生物機能概觀
脱氧核醣核酸於真核生物細胞內,通常是以長條狀染色體形式存在;在原核生物細胞內則是環狀染色體。細胞內的所有染色體合稱基因組。人類基因組中大約有30億個鹼基對,共組成了46個染色體[66]。脱氧核醣核酸所攜帶的訊息,是以脱氧核醣核酸序列形式,保存於一些稱為基因的片段中。基因中的遺傳訊息是經由互補的鹼基配對來傳遞,例如在轉錄作用中,細胞裡的RNA核苷酸會與互補的脱氧核醣核酸結合,複製出一段與脱氧核醣核酸序列互補的RNA序列。一般來說,這段RNA序列將會在轉譯作用中,經由RNA之間的互補配對,合成出相對應的蛋白質序列。另一方面,細胞也可以在稱為脱氧核醣核酸複製的過程中,單純地複製其自身的遺傳訊息。
基因組結構
真核生物的基因組脱氧核醣核酸主要存放於細胞核中,此外也有少量位於粒線體或葉綠體內。原核生物的脱氧核醣核酸則是保存在形狀不規則的類核(nucleoid)當中[67]。基因是脱氧核醣核酸的一段區域,保存了基因組裡的遺傳訊息,是遺傳的單位,影響了生物個體的特定表徵。基因中含有可轉錄的開放閱讀框架,以及一些可調節開放閱讀框架表現的調控序列,如啟動子與強化子。
許多物種的基因組都只有一小部分可編譯成蛋白質。以人類為例,在人類的基因組中只有1.5%屬於含有蛋白質編碼的外顯子,另有超過50%屬於無編碼的重複序列[68]。真核生物基因組中如此大量的非編碼DNA,以及物種之間不尋常的基因組大小或C值差異,長久以來一直是個難題,人們稱之為「C值謎」[69]。不過這些不含蛋白質編碼的脱氧核醣核酸序列,仍可能合成出具有功能的非編碼RNA分子,用以調控基因表現[70]。

T7RNA聚合酶(藍色)以脱氧核醣核酸模板(橙色)為依據,合成mRNA(綠色)[71]。
染色體中的某些非編碼脱氧核醣核酸序列,本身具有結構上的功能。例如一般只帶有少量基因的端粒與着絲粒,對於染色體的穩定性及機能而言顯得相當重要[46][72]。人類體內有一類大量存在的非編碼脱氧核醣核酸,稱為偽基因,是一些因突變累積而變得殘缺無用的基因複製品[73]。這些序列通常只可算是分子化石,不過有時候也會因為基因重複與趨異演化,而成為新基因裡的新遺傳物質[74]。
轉錄與轉譯
基因是指一段含有遺傳訊息,且可影響生物體表現型的脱氧核醣核酸序列。基因裡的脱氧核醣核酸鹼基序列決定了信使RNA的序列,而信使RNA的序列又決定了蛋白質的序列。轉譯作用可依據基因所含有的核苷酸序列,以及遺傳密碼規則,生產出對應的蛋白質氨基酸序列。遺傳密碼的組成單位稱為密碼子,是含有三個字母的「指令」,這些單位則由三個核苷酸組成,例如ACT、CAG或TTT。
在轉錄作用中,基因裡的密碼子會在RNA聚合酶的作用下,複製成為信使RNA。之後核醣體會幫助帶着氨基酸的轉移RNA與信使RNA進行鹼基配對,進而將信使RNA解碼。由於組成密碼子的鹼基共有四種,且以三字母為一單位,因此可能存在的密碼子一共有64種(43)。與這些密碼子對應的標準氨基酸有20種,因此大多數氨基酸對應了一種以上的密碼子。另外有三個密碼子稱為「終止密碼子」或「無義密碼子」,是編碼區域的末端,分別是TAA、TGA與TAG,這是屬於DNA上的終止密碼。而在mRNA上的則是UAG、UAA與UGA。當轉譯到達這三組密碼子時就會停止轉譯,並進行下一步的修飾。

圖為脱氧核醣核酸複製,首先螺旋酶與拓撲異構酶將雙螺旋解開,接着一個DNA聚合酶負責合成前進股;另一個則與延遲股結合,製造一些不連續的岡崎片段,再由脱氧核醣核酸連接酶將其黏合。
複製
生物個體成長需要經歷細胞分裂,當細胞進行分裂時,必須將自身基因組中的脱氧核醣核酸複製,才能使子細胞擁有和親代相同的遺傳訊息。脱氧核醣核酸的雙股結構可供脱氧核醣核酸複製機制進行,在此複製過程中,兩條長鏈會先分離,之後一種稱為DNA聚合酶的酵素,會分別以兩條長鏈為依據,合成出互補的脱氧核醣核酸序列。酵素可找出正確的外來互補鹼基,並將其結合到模板長鏈上,進而製造出新的互補長鏈。由於脱氧核醣核酸聚合酶只能以5'到3'的方向合成脱氧核醣核酸鏈,因此雙螺旋中平行但方向相反的兩股,具有不同的合成機制[75]。舊長鏈上的鹼基序列決定了新長鏈上的鹼基序列,使細胞得以獲得完整的脱氧核醣核酸複製品。
與蛋白質的交互作用
脱氧核醣核酸若要發揮其功用,必須仰賴與蛋白質之間的交互作用,有些蛋白質的作用不具專一性,有些則只專門與個別的脱氧核醣核酸序列結合。聚合酶在各類酵素中尤其重要,此種蛋白質可與脱氧核醣核酸結合,並作用於轉錄或脱氧核醣核酸複製過程。
脱氧核醣核酸結合蛋白
 |
結構蛋白可與脱氧核醣核酸結合,是非專一性脱氧核醣核酸-蛋白質交互作用的常見例子。染色體中的結構蛋白與脱氧核醣核酸組合成複合物,使脱氧核醣核酸組織成緊密結實的染色質構造。對真核生物來說,染色質是由脱氧核醣核酸與一種稱為組織蛋白的小型鹼性蛋白質所組合而成;而原核生物體內的此種結構,則掺杂了多種類型的蛋白質[76][77]。雙股脱氧核醣核酸可在組織蛋白的表面上附着並纏繞整整兩圈,以形成一種稱為核小體的盤狀複合物。組織蛋白裡的鹼性殘基,與脱氧核醣核酸上的酸性糖磷酸骨架之間可形成離子鍵,使兩者發生非專一性交互作用,也使複合物中的鹼基序列相互分離[78]。在鹼性氨基酸殘基上所發生的化學修飾有甲基化、磷酸化與乙醯化等[79],這些化學作用可使脱氧核醣核酸與組織蛋白之間的作用強度發生變化,進而使脱氧核醣核酸與轉錄因子接觸的難易度改變,影響轉錄作用的速率[80]。其他位於染色體內的非專一性脱氧核醣核酸結合蛋白,還包括一種能優先與脱氧核醣核酸結合,並使其扭曲的高移動性群蛋白[81]。這類蛋白質可以改變核小體的排列方式,產生更複雜的染色質結構[82]。
脱氧核醣核酸結合蛋白中有一種專門與單股脱氧核醣核酸結合的類型,稱為單股脱氧核醣核酸結合蛋白。人類的複製蛋白A是此類蛋白中獲得較多研究的成員,作用於多數與解開雙螺旋有關的過程,包括脱氧核醣核酸複製、重組以及脱氧核醣核酸修復[83]。這類結合蛋白可固定單股脱氧核醣核酸,使其變得較為穩定,以避免形成莖環(stem-loop),或是因為核酸酶的作用而水解。

λ抑制子是一類具螺旋-轉角-螺旋結構的轉錄因子,可與脱氧核醣核酸目標結合[84]。
相對而言,其他的蛋白質則只能與特定的脱氧核醣核酸序列進行專一性結合。大多數關於此類蛋白質的研究集中於各種可調控轉錄作用的轉錄因子。這類蛋白質中的每一種,都能與特定的脱氧核醣核酸序列結合,進而活化或抑制位於啟動子附近序列的基因轉錄作用。轉錄因子有兩種作用方式,第一種可以直接或經由其他中介蛋白質的作用,而與負責轉錄的RNA聚合酶結合,再使聚合酶與啟動子結合,並開啟轉錄作用[85]。第二種則與專門修飾組織蛋白的酵素結合於啟動子上,使脱氧核醣核酸模板與聚合酶發生接觸的難度改變[86]。
由於目標脱氧核醣核酸可能散佈在生物體中的整個基因組中,因此改變一種轉錄因子的活性可能會影響許多基因的運作[87]。這些轉錄因子也因此經常成為信號傳遞過程中的作用目標,也就是作為細胞反映環境改變,或是進行分化和發育時的媒介。具專一性的轉錄因子會與脱氧核醣核酸發生交互作用,使脱氧核醣核酸鹼基的周圍產生許多接觸點,讓其他蛋白質得以「讀取」這些脱氧核醣核酸序列。多數的鹼基交互作用發生在大凹槽,也就是最容易從外界接觸鹼基的部位[88]。

限制酶EcoRV(綠色)與其受質脱氧核醣核酸形成複合物[89]。
脱氧核醣核酸修飾酵素
核酸酶與連接酶
核酸酶是一種可經由催化磷酸雙酯鍵的水解,而將脱氧核醣核酸鏈切斷的酵素。其中一種稱為外切酶,可水解位於脱氧核醣核酸長鏈末端的核苷酸;另一種則是內切酶,作用於脱氧核醣核酸兩個端點之間的位置。在分子生物學領域中使用頻率最高的核酸酶為限制內切酶,可切割特定的脱氧核醣核酸序列。例如左圖中的EcoRV可辨識出具有6個鹼基的5′-GAT|ATC-3′序列,並從GAT與ATC之間那條垂直線所在的位置將其切斷。此類酵素在自然界中能消化噬菌體脱氧核醣核酸,以保護遭受噬菌體感染的細菌,此作用屬於限制修飾系統的一部分[90]。在技術上,對序列具專一性的核酸酶可應用於分子選殖與脱氧核醣核酸指紋分析。
另一種酵素脱氧核醣核酸連接酶,則可利用來自腺苷三磷酸或煙醯胺腺嘌呤二核苷酸的能量,將斷裂的脱氧核醣核酸長鏈重新接合[91]。連接酶對於脱氧核醣核酸複製過程中產生的延遲股而言尤其重要,這些位於複製叉上的短小片段,可在此酵素作用下黏合成為脱氧核醣核酸模板的完整複製品。此外連接酶也參與了DNA修復與遺傳重組作用[91]。
拓撲異構酶與螺旋酶
拓撲異構酶是一種同時具有核酸酶與連接酶效用的酵素,可改變脱氧核醣核酸的超螺旋程度。其中有些是先使脱氧核醣核酸雙螺旋的其中一股切開以形成缺口,讓另一股能穿過此缺口,進而減低超螺旋程度,最後再將切開的部位黏合[31]。其他類型則是將兩股脱氧核醣核酸同時切開,使另一條雙股脱氧核醣核酸得以通過此缺口,之後再將缺口黏合[92]。拓撲異構酶參與了許多脱氧核醣核酸相關作用,例如脱氧核醣核酸複製與轉錄[32]。
螺旋酶是分子馬達的一種類型,可利用來自各種核苷三磷酸,尤其是腺苷三磷酸的化學能量,破壞鹼基之間的氫鍵,使DNA雙螺旋解開成單股形式[93]。此類酵素參與了大多數關於DNA的作用,且必須接觸鹼基才能發揮功用。
聚合酶
聚合酶是一種利用核苷三磷酸來合成聚合苷酸鏈的酵素,方法是將一個核苷酸連接到另一個核苷酸的3'羥基位置,因此所有的聚合酶都是以5'往3'的方向進行合成作用[94]。在此類酵素的活化位置上,核苷三磷酸受質會與單股聚合苷酸模板發生鹼基配對,因而使聚合酶能夠精確地依據模板,合成出互補的另一股聚合苷酸。聚合酶可依據所能利用的模板類型來做分類。
在脱氧核醣核酸複製過程中,依賴脱氧核醣核酸模板的DNA聚合酶可合成出脱氧核醣核酸序列的複製品。由於此複製過程的精確性是生命維持所必需,因此許多這類聚合酶擁有校正功能,可辨識出合成反應中偶然發生的配置錯誤,也就是一些無法與另一股配對的鹼基。檢測出錯誤之後,其3'到5'方向的外切酶活性會發生作用,並將錯誤的鹼基移除[95]。大多數生物體內的脱氧核醣核酸聚合酶,是以稱為複製體的大型複合物形式來發生作用,此複合物中含有許多附加的次單位,如DNA夾或螺旋酶[96]。
依賴RNA作為模板的脱氧核醣核酸聚合酶是一種較特別的聚合酶,可將RNA長鏈的序列複製成脱氧核醣核酸版本。其中包括一種稱為逆轉錄酶的病毒酵素,此種酵素參與了逆轉錄病毒對細胞的感染過程;另外還有複製端粒所需的端粒酶[97][45],本身結構中含有RNA模板[46]。
轉錄作用是由依賴脱氧核醣核酸作為合成模板的RNA聚合酶來進行,此類酵素可將脱氧核醣核酸長鏈上的序列複製成RNA版本。為了起始一個基因的轉錄,RNA聚合酶會先與一段稱為啟動子的脱氧核醣核酸序列結合,並使兩股脱氧核醣核酸分離,再將基因序列複製成信使RNA,直到到達能使轉錄結束的終止子序列為止。如同人類體內依賴脱氧核醣核酸模板的脱氧核醣核酸聚合酶,負責轉錄人類基因組中大多數基因的RNA聚合酶II,也是大型蛋白質複合物的一部分,此複合物受到多重調控,也含有許多附加的次單位[98]。
遺傳重組
 |
 |
遺傳重組過程中產生的Holliday交叉結構,圖中的紅色、藍色、綠色與黃色分別表示四條不同的DNA長鏈[99]。

重組過程中,兩條染色體(M與F)斷裂之後又重新接合,產生兩條重新排列過的染色體(C1與C2)。
各條脱氧核醣核酸螺旋間的交互作用不常發生,在人類細胞核裡的每個染色體,各自擁有一塊稱作「染色體領域」的區域[100]。染色體之間在物理上的分離,對於維持脱氧核醣核酸資訊儲藏功能的穩定性而言相當重要。
不過染色體之間有時也會發生重組,在重組的過程中,會進行染色體互換:首先兩條脱氧核醣核酸螺旋會先斷裂,之後交換其片段,最後再重新黏合。重組作用使染色體得以互相交換遺傳訊息,並產生新的基因組合,進而增加自然選擇的效果,且可能對蛋白質的演化產生重要影響[101]。遺傳重組也參與脱氧核醣核酸修復作用,尤其是當細胞中的脱氧核醣核酸發生斷裂的時候[102]。
同源重組是最常見的染色體互換方式,可發生於兩條序列相類似的染色體上。而非同源重組則對細胞具有傷害性,會造成染色體易位與遺傳異常。可催化重組反應的酵素,如RAD51[103],稱為「重組酶」。重組作用的第一個步驟,是內切酶作用,或是脱氧核醣核酸的損壞所造成的脱氧核醣核酸雙股斷裂[104]。重組酶可催化一系列步驟,使兩條螺旋結合產生Holliday交叉。其中每條螺旋中的單股脱氧核醣核酸,皆與另一條螺旋上與之互補的脱氧核醣核酸連結在一起,進而形成一種可於染色體內移動的交叉形構造,造成脱氧核醣核酸鏈的互換。重組反應最後會因為交叉結構的斷裂,以及脱氧核醣核酸的重新黏合而停止[105]。
脱氧核醣核酸生物代謝的演化
脱氧核醣核酸所包含的遺傳訊息,是所有現代生命機能,以及生物生長與繁殖的基礎。不過目前尚未明瞭在長達40億年生命史中,脱氧核醣核酸究竟是何時出現並開始發生作用。有一些科學家認為,早期的生命形态有可能是以RNA作為遺傳物質[106][107]。RNA可能在早期細胞代謝中扮演主要角色,一方面可傳遞遺傳訊息;另一方面也可作為核醣酶的一部分,進行催化作用[108]。在古代RNA世界裡,核酸同時具有催化與遺傳上的功能,而這些分子後來可能演化成為目前以四種核苷酸組成遺傳密碼的形式,這是因為當鹼基種類較少時,複製的精確性會增加;而鹼基種類較多時,增加的則是核酸的催化效能。兩種可達成不同目的功能最後在四種鹼基的情形下達到最合適數量[109]。
不過關於這種古代遺傳系統並沒有直接證據,且由於脱氧核醣核酸在環境中無法存留超過一百萬年,在溶液中又會逐漸降解成短小的片段,因此大多數化石中並無脱氧核醣核酸可供研究[110]。即使如此,仍有一些聲稱表示已經獲得更古老的DNA,其中一項研究表示,已從存活於2億5千萬年古老的鹽類晶體中的細菌分離出脱氧核醣核酸[111],但此宣布引起了討論與爭議[112][113]。
技術應用
遺傳工程
重組脱氧核醣核酸技術在現代生物學與生物化學中受到廣泛應用,所謂重組DNA,是指集合其他脱氧核醣核酸序列所製成的人造脱氧核醣核酸,可以质粒或以病毒載體搭載所想要的格式,將脱氧核醣核酸轉型到生物個體中[114]。經過遺傳改造處裡之後的生物體,可用來生產重組蛋白質,以供醫學研究使用[115],或是於農業上栽種[116][117]。
法醫鑑識
法醫可利用犯罪現場遺留的血液、精液、皮膚、唾液或毛髮中的脱氧核醣核酸,來辨識可能的加害人。此過程稱為遺傳指紋分析或脱氧核醣核酸特徵測定,此分析方法比較不同人類個體中許多的重複脱氧核醣核酸片段的長度,這些脱氧核醣核酸片段包括短串聯重複序列與小衛星序列等,一般來說是最為可靠的罪犯辨識技術[118]。不過如果犯罪現場遭受多人的脱氧核醣核酸污染,那麼將會變得較為複雜難解[119]。
首先於1984年發展脱氧核醣核酸特徵測定的人是一名英國遺傳學家阿萊克·傑弗里斯[120]。到了1988年,英國的謀殺案嫌犯科林·皮奇福克,成為第一位因脱氧核醣核酸特徵測定證據而遭定罪者[121]。利用特定類型犯罪者的脱氧核醣核酸樣本,可建立出資料庫,幫助調查者解決一些只從現場採集到脱氧核醣核酸樣本的舊案件。此外,脱氧核醣核酸特徵測定也可用來辨識重大災害中的罹難者[122]。
另外,有保險公司利用DNA鑑識技術,以確認理賠責任歸屬。相關事例包括:年僅16歲的臺灣少年Lien-Yang Lee於2013年9月在澳洲遭遇車禍,他在申報保險理賠時聲稱,事故發生時他是坐後排乘客座上;不過,RACQ保險公司指駕駛座前安全氣囊上血跡的DNA,是屬於Lien-Yang Lee,故推斷在車禍發生時他是坐在前排駕駛座上;故此,RACQ保險公司指他涉及詐欺,拒絕支付相關醫療費用;隨後昆士蘭州高等法院亦於2017年3月確認,Lien-Yang Lee在事故發生時涉及無照駕駛。[123]
歷史學與人類學
由於脱氧核醣核酸在經歷一段時間後會積聚一些具有遺傳能力突變,因此其中所包含的歷史訊息,可經由脱氧核醣核酸序列的比較,使遺傳學家瞭解生物體的演化歷史,也就是種系[124]。這些研究是種系發生學的一部分,也是演化生物學上的有利工具。假如對物種以內範圍的脱氧核醣核酸序列進行比較,那麼群體遺傳學家就可得知特定族群的歷史。此方法的應用範圍可從生態遺傳學到人類學,舉例而言,脱氧核醣核酸證據已被試圖用來尋找失蹤的以色列十支派[125][126]。DNA也可以用來調查現代家族的親戚關係,例如建構莎麗·海明斯與托马斯·杰斐逊的後代之間的家族關係,研究方式則與上述的犯罪調查相當類似,因此有時候某些犯罪調查案件之所以能解決,是因為犯罪現場的脱氧核醣核酸與犯罪者親屬的脱氧核醣核酸相符[127]。
生物資訊學
生物資訊學影響了脱氧核醣核酸序列資料的運用、搜尋與資料挖掘工作,並發展出各種用於儲存並搜尋脱氧核醣核酸序列的技術,可進一步應用於電腦科學,尤其是字串搜尋演算法、機器學習以及資料庫理論[128]。字串搜尋或比對演算法是從較大的序列或較多的字母中,尋找單一序列或少數字母的出現位置,可發展用來搜尋特定的核苷酸序列[129]。在其他如文本編輯器的應用裡,通常可用簡單的演算法來解決問題,但只有少量可辨識特徵的脱氧核醣核酸序列,卻造成這些演算法的運作不良。序列比對則試圖辨識出同源序列,並定位出使這些序列產生差異的特定突變位置,其中的多重序列比對技術可用來研究種系發生關係及蛋白質的功能[130]。由整個基因組所構成的資料含有的大量脱氧核醣核酸序列,例如人類基因組計畫的研究對象。若要將每個染色體上的每個基因,以及負責調控基因的位置都標示出來,會相當困難。脱氧核醣核酸序列上具有蛋白質或RNA編碼特徵的區域,可利用基因識別演算法辨識出來,使研究者得以在進行實驗以前,就預測出生物體內可能表現出來的特殊基因產物[131]。
脱氧核醣核酸與電腦

自我組裝產生的脱氧核醣核酸纳米結構。左方為電腦繪圖,可見4條由脱氧核醣核酸雙螺旋產生的交叉。右方為原子力顯微鏡測得的影像。圖像来自Strong, 2004 .
脱氧核醣核酸最早在運算上應用,是解決了一個屬於NP完全的小型直接漢彌爾頓路徑問題[132]。脱氧核醣核酸可作為「軟體」,將訊息寫成核苷酸序列;並以酵素或其他分子作為「硬體」進行讀取或修飾。舉例來說,作為硬體的限制酶FokI可以搭載一段具有軟體功能的GGATG序列脱氧核醣核酸,再以其他的脱氧核醣核酸片段進行輸入,並與軟硬體複合物產生反應,最後輸出另一段脱氧核醣核酸[133]。這種類似圖靈機的裝置可應用於藥物治療。此外脱氧核醣核酸運算在能源消耗、空間需求以及效率上優於電子電腦,且脱氧核醣核酸運算為具有高度平行(見平行運算)的計算方式。許多其他問題,包括多種抽象機器的模擬、布爾可滿足性問題,以及有界形式的旅行推銷員問題,皆曾利用脱氧核醣核酸運算做过分析[134]。由於小巧緊密的特性,脱氧核醣核酸也成為密碼學理論的一部分,尤其在於能夠利用脱氧核醣核酸有效地建構並使用無法破解的一次性密碼本[135]。
脱氧核醣核酸與纳米科技
脱氧核醣核酸的分子性質,例如自我組裝特性,使其可用於某些纳米尺度的建構技術,例如利用脱氧核醣核酸作為模板,可導引半導體晶體的生長[136]。或是利用脱氧核醣核酸本身,來製成一些特殊結構,例如由脱氧核醣核酸長鏈交叉形成的脱氧核醣核酸「瓦片」(tile)[137]或是多面體[138]。此外也可以做出一些可活動的元件,例如纳米機械開關,此機械可經由使脱氧核醣核酸在不同的光學異構物(B型與Z型)之間進行轉變,而使構形發生變化,導致開關的開啟或關閉[139]。還有一種脱氧核醣核酸機械含有類似鑷子的構造,可加入外來脱氧核醣核酸使鑷子開合,並排出廢物脱氧核醣核酸,此時脱氧核醣核酸的作用類似「燃料」[140]。脱氧核醣核酸所建構出來的裝置,也可用來作為上述的脱氧核醣核酸運算工具。
歷史

双螺旋模型的共同原创者:詹姆斯·沃森和弗朗西斯·克里克(右),他们与Maclyn McCart(左)。
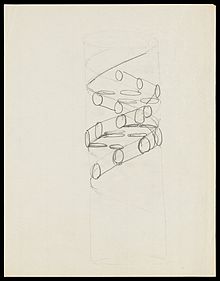
在1953年由弗朗西斯·克里克画的DNA双螺旋结构的铅笔素描。
最早分離出脱氧核醣核酸的弗雷德里希·米歇爾是一名瑞士醫生,他在1869年,從廢棄繃帶裡所殘留的膿液中,發現一些只有顯微鏡可觀察的物質。由於這些物質位於細胞核中,因此米歇爾稱之為「核素」(nuclein)[141]。到了1919年,菲巴斯·利文進一步辨識出組成脱氧核醣核酸的鹼基、糖類以及磷酸核苷酸單元[142],他認為脱氧核醣核酸可能是許多核苷酸經由磷酸基團的联结,而串聯在一起。不過他所提出概念中,脱氧核醣核酸長鏈較短,且其中的鹼基是以固定順序重複排列。1937年,威廉·阿斯特伯里完成了第一張X光繞射圖,闡明了脱氧核醣核酸結構的規律性[143]。
1928年,弗雷德里克·格里菲斯從格里菲斯實驗中發現,平滑型的肺炎球菌,能轉變成為粗糙型的同種細菌,方法是將已死的平滑型與粗糙型活體混合在一起。這種現象稱為「轉型」。但造成此現象的因子,也就是脱氧核醣核酸,是直到1943年,才由奧斯瓦爾德·埃弗里等人所辨識出來[144]。1953年,阿弗雷德·赫希與瑪莎·蔡斯確認了脱氧核醣核酸的遺傳功能,他們在赫希-蔡斯實驗中發現,脱氧核醣核酸是T2噬菌體的遺傳物質[145]。
到了1953年,當時在卡文迪許實驗室的詹姆斯·沃森與佛朗西斯·克里克,依據倫敦國王學院的羅莎琳·富蘭克林所拍攝的X光繞射圖[146]及相關資料,提出了[146]最早的核酸分子結構精確模型,並發表於《自然》期刊[6]。五篇關於此模型的實驗證據論文,也同時以同一主題發表於《自然》[147]。其中包括富蘭克林與雷蒙·葛斯林的論文[148],此文所附帶的X光繞射圖[149],是沃森與克里克闡明脱氧核醣核酸結構的關鍵證據。此外莫里斯·威爾金斯團隊也是同期論文的發表者之一[150]。富蘭克林與葛斯林隨後又提出了A型與B型脱氧核醣核酸雙螺旋結構之間的差異[151]。1962年,沃森、克里克以及威爾金斯共同獲得了諾貝爾生理學或醫學獎[152]。
克里克在1957年的一場演說中,提出了分子生物學的中心法則,預測了脱氧核醣核酸、RNA以及蛋白質之間的關係,並闡述了「轉接子假說」(即後來的tRNA)[153]。1958年,馬修·梅瑟生與富蘭克林·史達在梅瑟生-史達實驗中,確認了脱氧核醣核酸的複製機制[154]。後來克里克團隊的研究顯示,遺傳密碼是由三個鹼基以不重複的方式所組成,稱為密碼子。這些密碼子所構成的遺傳密碼,最後是由哈爾·葛賓·科拉納、羅伯特·W·霍利以及馬歇爾·沃倫·尼倫伯格解出[155]。這些發現代表了分子生物學的誕生。
為了測出所有人類的脱氧核醣核酸序列,人類基因組計畫於1990年代展開。到了2001年,多國合作的國際團隊與私人企業塞雷拉基因組公司,分別將人類基因組序列草圖發表於《自然》[156]與《科學》[157]兩份期刊。
参见
- 常染色体
- 遺傳性疾病
- DNA測序
- 南方墨點法
- DNA微陣列
- 聚合酶链式反应
- 减数分裂
- 泛生論
- X射线衍射法
- 环状DNA
參考文獻
^ Matt Ridley。蔡承志、許優優譯。《23對染色體》(Genome)。商周出版。2000年。ISBN 978-957-667-678-9
^ 2.02.1 Alberts, Bruce; Alexander Johnson; Julian Lewis; Martin Raff; Keith Roberts; Peter Walters. Molecular Biology of the Cell; Fourth Edition. New York and London: Garland Science. 2002. ISBN 978-0-8153-3218-3.
^ Butler, John M. (2001) Forensic DNA Typing "Elsevier". pp. 14 – 15. ISBN 978-0-12-147951-0.
^ Mandelkern M, Elias J, Eden D, Crothers D. The dimensions of DNA in solution. J Mol Biol. 1981, 152 (1): 153 – 61. PMID 7338906.
^ Gregory S; 等. The DNA sequence and biological annotation of human chromosome 1. Nature. 2006, 441 (7091): 315 – 21. PMID 16710414.
^ 6.06.1 Watson J, Crick F. Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid (PDF). Nature. 1953, 171 (4356): 737 – 8. PMID 13054692.
^ 7.07.17.2 Berg J., Tymoczko J. and Stryer L. (2002) Biochemistry. W. H. Freeman and Company ISBN 0-7167-4955-6
^ 8.08.1 Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Accessed 03 Jan 2006
^ 9.09.1 Ghosh A, Bansal M. A glossary of DNA structures from A to Z. Acta Crystallogr D Biol Crystallogr. 2003, 59 (Pt 4): 620 – 6. PMID 12657780.
^ 10.010.1 薛金星. 中学教材全解 工具版 高中生物必修1 分子与细胞. 陕西人民教育出版社. ISBN 9787545015751.
^ 11.011.111.211.311.4 人民教育出版社. 生物1 必修 分子与细胞. ISBN 9787107176708.
^ 生命的螺旋-DNA與RNA. 國立科學工藝博物館.
^ Takahashi I, Marmur J. Replacement of thymidylic acid by deoxyuridylic acid in the deoxyribonucleic acid of a transducing phage for Bacillus subtilis. Nature. 1963, 197: 794 – 5. PMID 13980287.
^ Agris P. Decoding the genome: a modified view. Nucleic Acids Res. 2004, 32 (1): 223 – 38. PMID 14715921.
^ 來源:PDB 1D65[永久失效連結]
^ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson R. Crystal structure analysis of a complete turn of B-DNA. Nature. 1980, 287 (5784): 755 – 8. PMID 7432492.
^ Pabo C, Sauer R. Protein-DNA recognition. Annu Rev Biochem: 293 – 321. PMID 6236744.
^ Ponnuswamy P, Gromiha M. On the conformational stability of oligonucleotide duplexes and tRNA molecules. J Theor Biol. 1994, 169 (4): 419 – 32. PMID 7526075.
^ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub H. Mechanical stability of single DNA molecules. Biophys J. 2000, 78 (4): 1997 – 2007. PMID 10733978.
^ Chalikian T, Völker J, Plum G, Breslauer K. A more unified picture for the thermodynamics of nucleic acid duplex melting: a characterization by calorimetric and volumetric techniques. Proc Natl Acad Sci U S A. 1999, 96 (14): 7853 – 8. PMID 10393911.
^ deHaseth P, Helmann J. Open complex formation by Escherichia coli RNA polymerase: the mechanism of polymerase-induced strand separation of double helical DNA. Mol Microbiol. 1995, 16 (5): 817 – 24. PMID 7476180.
^ Isaksson J, Acharya S, Barman J, Cheruku P, Chattopadhyaya J. Single-stranded adenine-rich DNA and RNA retain structural characteristics of their respective double-stranded conformations and show directional differences in stacking pattern. Biochemistry. 2004, 43 (51): 15996 – 6010. PMID 15609994.
^ Hüttenhofer A, Schattner P, Polacek N. Non-coding RNAs: hope or hype?. Trends Genet. 2005, 21 (5): 289 – 97. PMID 15851066.
^ Munroe S. Diversity of antisense regulation in eukaryotes: multiple mechanisms, emerging patterns. J Cell Biochem. 2004, 93 (4): 664 – 71. PMID 15389973.
^ Makalowska I, Lin C, Makalowski W. Overlapping genes in vertebrate genomes. Comput Biol Chem. 2005, 29 (1): 1 – 12. PMID 15680581.
^ Johnson Z, Chisholm S. Properties of overlapping genes are conserved across microbial genomes. Genome Res. 2004, 14 (11): 2268 – 72. PMID 15520290.
^ Lamb R, Horvath C. Diversity of coding strategies in influenza viruses. Trends Genet. 1991, 7 (8): 261 – 6. PMID 1771674.
^ Davies J, Stanley J. Geminivirus genes and vectors. Trends Genet. 1989, 5 (3): 77 – 81. PMID 2660364.
^ Berns K. Parvovirus replication. Microbiol Rev. 1990, 54 (3): 316 – 29. PMID 2215424.
^ Benham C, Mielke S. DNA mechanics. Annu Rev Biomed Eng: 21 – 53. PMID 16004565.
^ 31.031.1 Champoux J. DNA topoisomerases: structure, function, and mechanism. Annu Rev Biochem: 369 – 413. PMID 11395412.
^ 32.032.1 Wang J. Cellular roles of DNA topoisomerases: a molecular perspective. Nat Rev Mol Cell Biol. 2002, 3 (6): 430 – 40. PMID 12042765.
^ 33.033.1 Hayashi G, Hagihara M, Nakatani K. Application of L-DNA as a molecular tag. Nucleic Acids Symp Ser (Oxf). 2005, 49: 261 – 262. PMID 17150733.
^ Vargason JM, Eichman BF, Ho PS. The extended and eccentric E-DNA structure induced by cytosine methylation or bromination. Nature Structural Biology. 2000, 7: 758 – 761. PMID 10966645.
^ Wang G, Vasquez KM. Non-B DNA structure-induced genetic instability. Mutat Res. 2006, 598 (1 – 2): 103 – 119. PMID 16516932.
^ Allemand; 等. Stretched and overwound DNA forms a Pauling-like structure with exposed bases. PNAS. 1998, 24: 14152–14157. PMID 9826669.
^ Palecek E. Local supercoil-stabilized DNA structures. Critical Reviews in Biochemistry and Molecular Biology. 1991, 26 (2): 151 – 226. PMID 1914495.
^ Basu H, Feuerstein B, Zarling D, Shafer R, Marton L. Recognition of Z-RNA and Z-DNA determinants by polyamines in solution: experimental and theoretical studies. J Biomol Struct Dyn. 1988, 6 (2): 299 – 309. PMID 2482766.
^ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL. Polymorphism of DNA double helices. J. Mol. Biol. 1980, 143 (1): 49–72. PMID 7441761.
^ Wahl M, Sundaralingam M. Crystal structures of A-DNA duplexes. Biopolymers. 1997, 44 (1): 45 – 63. PMID 9097733.
^ Lu XJ, Shakked Z, Olson WK. A-form conformational motifs in ligand-bound DNA structures. J. Mol. Biol. 2000, 300 (4): 819–40. PMID 10891271.
^ Rothenburg S, Koch-Nolte F, Haag F. DNA methylation and Z-DNA formation as mediators of quantitative differences in the expression of alleles. Immunol Rev: 286 – 98. PMID 12086319.
^ Oh D, Kim Y, Rich A. Z-DNA-binding proteins can act as potent effectors of gene expression in vivo. Proc. Natl. Acad. Sci. U.S.A. 2002, 99 (26): 16666–71. PMID 12486233.
^ 來自NDB UD0017 互联网档案馆的存檔,存档日期2007-10-12.
^ 45.045.1 Greider C, Blackburn E. Identification of a specific telomere terminal transferase activity in Tetrahymena extracts. Cell. 1985, 43 (2 Pt 1): 405 – 13. PMID 3907856.
^ 46.046.146.2 Nugent C, Lundblad V. The telomerase reverse transcriptase: components and regulation. Genes Dev. 1998, 12 (8): 1073 – 85. PMID 9553037.
^ Wright W, Tesmer V, Huffman K, Levene S, Shay J. Normal human chromosomes have long G-rich telomeric overhangs at one end. Genes Dev. 1997, 11 (21): 2801 – 9. PMID 9353250.
^ 48.048.1 Burge S, Parkinson G, Hazel P, Todd A, Neidle S. Quadruplex DNA: sequence, topology and structure. Nucleic Acids Res. 2006, 34 (19): 5402 – 15. PMID 17012276.
^ Parkinson G, Lee M, Neidle S. Crystal structure of parallel quadruplexes from human telomeric DNA. Nature. 2002, 417 (6891): 876 – 80. PMID 12050675.
^ Griffith J, Comeau L, Rosenfield S, Stansel R, Bianchi A, Moss H, de Lange T. Mammalian telomeres end in a large duplex loop. Cell. 1999, 97 (4): 503 – 14. PMID 10338214.
^ Klose R, Bird A. Genomic DNA methylation: the mark and its mediators. Trends Biochem Sci. 2006, 31 (2): 89–97. PMID 16403636.
^ Bird A. DNA methylation patterns and epigenetic memory. Genes Dev. 2002, 16 (1): 6–21. PMID 11782440.
^ Walsh C, Xu G. Cytosine methylation and DNA repair. Curr Top Microbiol Immunol: 283–315. PMID 16570853.
^ Ratel D, Ravanat J, Berger F, Wion D. N6-methyladenine: the other methylated base of DNA. Bioessays. 2006, 28 (3): 309–15. PMID 16479578.
^ Gommers-Ampt J, Van Leeuwen F, de Beer A, Vliegenthart J, Dizdaroglu M, Kowalak J, Crain P, Borst P. beta-D-glucosyl-hydroxymethyluracil: a novel modified base present in the DNA of the parasitic protozoan T. brucei. Cell. 1993, 75 (6): 1129–36. PMID 8261512.
^ 來源:PDB 1JDG
^ Douki T, Reynaud-Angelin A, Cadet J, Sage E. Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation. Biochemistry. 2003, 42 (30): 9221–6. PMID 12885257.
^ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget J, Ravanat J, Sauvaigo S. Hydroxyl radicals and DNA base damage. Mutat Res. 1999, 424 (1–2): 9–21. PMID 10064846.
^ Shigenaga M, Gimeno C, Ames B. Urinary 8-hydroxy-2′-deoxyguanosine as a biological marker of in vivo oxidative DNA damage (PDF). Proc Natl Acad Sci U S A. 1989, 86 (24): 9697–701. PMID 2602371.
^ Cathcart R, Schwiers E, Saul R, Ames B. Thymine glycol and thymidine glycol in human and rat urine: a possible assay for oxidative DNA damage (PDF). Proc Natl Acad Sci U S A. 1984, 81 (18): 5633–7. PMID 6592579.
^ Valerie K, Povirk L. Regulation and mechanisms of mammalian double-strand break repair. Oncogene. 2003, 22 (37): 5792–812. PMID 12947387.
^ Ferguson L, Denny W. The genetic toxicology of acridines. Mutat Res. 1991, 258 (2): 123–60. PMID 1881402.
^ Jeffrey A. DNA modification by chemical carcinogens. Pharmacol Ther. 1985, 28 (2): 237–72. PMID 3936066.
^ Stephens T, Bunde C, Fillmore B. Mechanism of action in thalidomide teratogenesis. Biochem Pharmacol. 2000, 59 (12): 1489–99. PMID 10799645.
^ Braña M, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A. Intercalators as anticancer drugs. Curr Pharm Des. 2001, 7 (17): 1745–80. PMID 11562309.
^ Venter J; 等. The sequence of the human genome. Science. 2001, 291 (5507): 1304–51. PMID 11181995.
^ Thanbichler M, Wang S, Shapiro L. The bacterial nucleoid: a highly organized and dynamic structure. J Cell Biochem. 2005, 96 (3): 506–21. PMID 15988757.
^ Wolfsberg T, McEntyre J, Schuler G. Guide to the draft human genome. Nature. 2001, 409 (6822): 824–6. PMID 11236998.
^ Gregory T. The C-value enigma in plants and animals: a review of parallels and an appeal for partnership. Ann Bot (Lond). 2005, 95 (1): 133–46. PMID 15596463.
^ The ENCODE Project Consortium. Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature. 2007, 447 (7146): 799–816. doi:10.1038/nature05874.
^ 來源:PDB 1MSW
^ Pidoux A, Allshire R. The role of heterochromatin in centromere function (PDF). Philos Trans R Soc Lond B Biol Sci. 2005, 360 (1455): 569–79. PMID 15905142. [失效連結]
^ Harrison P, Hegyi H, Balasubramanian S, Luscombe N, Bertone P, Echols N, Johnson T, 马克·本德·歌诗坦. Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22. Genome Res. 2002, 12 (2): 272–80. PMID 11827946.
^ Harrison P, 马克·本德·歌诗坦. Studying genomes through the aeons: protein families, pseudogenes and proteome evolution. J Mol Biol. 2002, 318 (5): 1155–74. PMID 12083509.
^ Albà M. Replicative DNA polymerases. Genome Biol. 2001, 2 (1): REVIEWS3002. PMID 11178285.
^ Sandman K, Pereira S, Reeve J. Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome. Cell Mol Life Sci. 1998, 54 (12): 1350–64. PMID 9893710.
^ Dame RT. The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin. Mol. Microbiol. 2005, 56 (4): 858–70. PMID 15853876.
^ Luger K, Mäder A, Richmond R, Sargent D, Richmond T. Crystal structure of the nucleosome core particle at 2.8 A resolution. Nature. 1997, 389 (6648): 251–60. PMID 9305837.
^ Jenuwein T, Allis C. Translating the histone code. Science. 2001, 293 (5532): 1074–80. PMID 11498575.
^ Ito T. Nucleosome assembly and remodelling. Curr Top Microbiol Immunol: 1–22. PMID 12596902.
^ Thomas J. HMG1 and 2: architectural DNA-binding proteins. Biochem Soc Trans. 2001, 29 (Pt 4): 395–401. PMID 11497996.
^ Grosschedl R, Giese K, Pagel J. HMG domain proteins: architectural elements in the assembly of nucleoprotein structures. Trends Genet. 1994, 10 (3): 94–100. PMID 8178371.
^ Iftode C, Daniely Y, Borowiec J. Replication protein A (RPA): the eukaryotic SSB. Crit Rev Biochem Mol Biol. 1999, 34 (3): 141–80. PMID 10473346.
^ 來源:PDB 1LMB
^ Myers L, Kornberg R. Mediator of transcriptional regulation. Annu Rev Biochem: 729–49. PMID 10966474.
^ Spiegelman B, Heinrich R. Biological control through regulated transcriptional coactivators. Cell. 2004, 119 (2): 157–67. PMID 15479634.
^ Li Z, Van Calcar S, Qu C, Cavenee W, Zhang M, Ren B. A global transcriptional regulatory role for c-Myc in Burkitt's lymphoma cells. Proc Natl Acad Sci U S A. 2003, 100 (14): 8164–9. PMID 12808131.
^ Pabo C, Sauer R. Protein-DNA recognition. Annu Rev Biochem: 293–321. PMID 6236744.
^ Created from PDB 1RVA
^ Bickle T, Krüger D. Biology of DNA restriction. Microbiol Rev. 1993, 57 (2): 434–50. PMID 8336674.
^ 91.091.1 Doherty A, Suh S. Structural and mechanistic conservation in DNA ligases.. Nucleic Acids Res. 2000, 28 (21): 4051–8. PMID 11058099.
^ Schoeffler A, Berger J. Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism. Biochem Soc Trans. 2005, 33 (Pt 6): 1465–70. PMID 16246147.
^ Tuteja N, Tuteja R. Unraveling DNA helicases. Motif, structure, mechanism and function. Eur J Biochem. 2004, 271 (10): 1849–63. PMID 15128295. [永久失效連結]
^ Joyce C, Steitz T. Polymerase structures and function: variations on a theme?. J Bacteriol. 1995, 177 (22): 6321–9. PMID 7592405.
^ Hubscher U, Maga G, Spadari S. Eukaryotic DNA polymerases. Annu Rev Biochem: 133–63. PMID 12045093.
^ Johnson A, O'Donnell M. Cellular DNA replicases: components and dynamics at the replication fork. Annu Rev Biochem: 283–315. PMID 15952889.
^ Tarrago-Litvak L, Andréola M, Nevinsky G, Sarih-Cottin L, Litvak S. The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention. FASEB J. 1994, 8 (8): 497–503. PMID 7514143.
^ Martinez E. Multi-protein complexes in eukaryotic gene transcription. Plant Mol Biol. 2002, 50 (6): 925–47. PMID 12516863.
^ 來源:PDB 1M6G
^ Cremer T, Cremer C. Chromosome territories, nuclear architecture and gene regulation in mammalian cells. Nat Rev Genet. 2001, 2 (4): 292–301. PMID 11283701.
^ Pál C, Papp B, Lercher M. An integrated view of protein evolution. Nat Rev Genet. 2006, 7 (5): 337–48. PMID 16619049.
^ O'Driscoll M, Jeggo P. The role of double-strand break repair - insights from human genetics. Nat Rev Genet. 2006, 7 (1): 45–54. PMID 16369571.
^ Vispé S, Defais M. Mammalian Rad51 protein: a RecA homologue with pleiotropic functions. Biochimie. 1997, 79 (9-10): 587–92. PMID 9466696.
^ Neale MJ, Keeney S. Clarifying the mechanics of DNA strand exchange in meiotic recombination. Nature. 2006, 442 (7099): 153–8. PMID 16838012.
^ Dickman M, Ingleston S, Sedelnikova S, Rafferty J, Lloyd R, Grasby J, Hornby D. The RuvABC resolvasome. Eur J Biochem. 2002, 269 (22): 5492–501. PMID 12423347.
^ Joyce G. The antiquity of RNA-based evolution. Nature. 2002, 418 (6894): 214–21. PMID 12110897.
^ Orgel L. Prebiotic chemistry and the origin of the RNA world (PDF). Crit Rev Biochem Mol Biol: 99–123. PMID 15217990. (原始内容 (PDF)存档于2007-07-10).
^ Davenport R. Ribozymes. Making copies in the RNA world. Science. 2001, 292 (5520): 1278. PMID 11360970.
^ Szathmáry E. What is the optimum size for the genetic alphabet? (PDF). Proc Natl Acad Sci U S A. 1992, 89 (7): 2614–8. PMID 1372984.
^ Lindahl T. Instability and decay of the primary structure of DNA. Nature. 1993, 362 (6422): 709–15. PMID 8469282.
^ Vreeland R, Rosenzweig W, Powers D. Isolation of a 250 million-year-old halotolerant bacterium from a primary salt crystal. Nature. 2000, 407 (6806): 897–900. PMID 11057666.
^ Hebsgaard M, Phillips M, Willerslev E. Geologically ancient DNA: fact or artefact?. Trends Microbiol. 2005, 13 (5): 212–20. PMID 15866038.
^ Nickle D, Learn G, Rain M, Mullins J, Mittler J. Curiously modern DNA for a "250 million-year-old" bacterium. J Mol Evol. 2002, 54 (1): 134–7. PMID 11734907.
^ Goff SP, Berg P. Construction of hybrid viruses containing SV40 and lambda phage DNA segments and their propagation in cultured monkey cells. Cell. 1976, 9 (4 PT 2): 695–705. PMID 189942.
^ Houdebine L. Transgenic animal models in biomedical research. Methods Mol Biol: 163–202. PMID 17172731.
^ Daniell H, Dhingra A. Multigene engineering: dawn of an exciting new era in biotechnology. Curr Opin Biotechnol. 2002, 13 (2): 136–41. PMID 11950565.
^ Job D. Plant biotechnology in agriculture. Biochimie. 2002, 84 (11): 1105–10. PMID 12595138.
^ Collins A, Morton N. Likelihood ratios for DNA identification (PDF). Proc Natl Acad Sci U S A. 1994, 91 (13): 6007–11. PMID 8016106.
^ Weir B, Triggs C, Starling L, Stowell L, Walsh K, Buckleton J. Interpreting DNA mixtures. J Forensic Sci. 1997, 42 (2): 213–22. PMID 9068179.
^ Jeffreys A, Wilson V, Thein S. Individual-specific 'fingerprints' of human DNA.. Nature: 76–9. PMID 2989708.
^ Colin Pitchfork — first murder conviction on DNA evidence also clears the prime suspect 互联网档案馆的存檔,存档日期2006-12-14. Forensic Science Service Accessed 23 Dec 2006
^ DNA Identification in Mass Fatality Incidents. National Institute of Justice. September 2006. (原始内容存档于2006-11-12).
^ Legal Frontline 法律前線通訊社. MAY 4 少年無照駕駛佯稱父親肇事 --- 血跡DNA揭謊言保險公司拒賠.
^ Wray G. Dating branches on the tree of life using DNA. Genome Biol. 2002, 3 (1): REVIEWS0001. PMID 11806830.
^ Lost Tribes of Israel, NOVA, PBS airdate: 22 February 2000. Transcript available from PBS.org, (last accessed on 4 March 2006)
^ Kleiman, Yaakov. "The Cohanim/DNA Connection: The fascinating story of how DNA studies confirm an ancient biblical tradition". aish.com (January 13, 2000). Accessed 4 March 2006.
^ Bhattacharya, Shaoni. "Killer convicted thanks to relative's DNA". newscientist.com (20 April 2004). Accessed 22 Dec 06
^ Baldi, Pierre. Brunak, Soren. Bioinformatics: The Machine Learning Approach MIT Press (2001) ISBN 978-0-262-02506-5
^ Gusfield, Dan. Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press, 15 January 1997. ISBN 978-0-521-58519-4.
^ Sjölander K. Phylogenomic inference of protein molecular function: advances and challenges. Bioinformatics. 2004, 20 (2): 170–9. PMID 14734307.
^ Mount DM. Bioinformatics: Sequence and Genome Analysis 2. Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. 2004. ISBN 0879697121.
^ Adleman L. Molecular computation of solutions to combinatorial problems. Science. 1994, 266 (5187): 1021–4. PMID 7973651.
^ Benenson Y, Paz-Elizur T, Adar R, Keinan E, Livneh Z, Shapiro E. Programmable and autonomous computingmachine made of biomolecules. Nature. 2001, 414: 430–434.
^ Parker J. Computing with DNA.. EMBO Rep. 2003, 4 (1): 7–10. PMID 12524509.
^ Ashish Gehani, Thomas LaBean and John Reif. DNA-Based Cryptography.
Proceedings of the 5th DIMACS Workshop on DNA Based Computers, Cambridge, MA, USA, 14–15 June 1999.
^ Coffer, J. L.; 等. Dictation of the shape of mesoscale semiconductor nanoparticle assemblies by plasmid DNA. Appl. Phys. Lett. 1996, 69: 3851–3853.
^ Strong M. Protein Nanomachines. PLoS Biology. 2004, 2: e73.
^ Chen J, Seeman NC. Synthesis from DNA of a molecule with the connectivity of a cube. Nature. 1991, 350: 631–633.
^ Mao C, Sun W, Shen Z, Seeman NC. A nanomechanical device based on the B-Z transition of DNA. Nature. 1999, 397: 144–146.
^ Bernard Yurke, Andrew J. Turberfield, Allen P. Mills, Jr, Friedrich C. Simmel and Jennifer L. Neumann. A DNA-Fuelled Molecular Machine Made of DNA. Nature. 2000, 406: 605–608.
^ Dahm R. Friedrich Miescher and the discovery of DNA. Dev Biol. 2005, 278 (2): 274–88. PMID 15680349.
^ Levene P,. The structure of yeast nucleic acid. J Biol Chem. 1919, 40 (2): 415–24.
^ Astbury W,. Nucleic acid. Symp. SOC. Exp. Bbl. 1947, 1 (66).
^ Avery O, MacLeod C, McCarty M. Studies on the chemical nature of the substance inducing transformation of pneumococcal types. Inductions of transformation by a desoxyribonucleic acid fraction isolated from pneumococcus type III. J Exp Med. 1944, 79 (2): 137–158.
^ Hershey A, Chase M. Independent functions of viral protein and nucleic acid in growth of bacteriophage (PDF). J Gen Physiol. 1952, 36 (1): 39–56. PMID 12981234.
^ 146.0146.1 Watson J.D. and Crick F.H.C. "A Structure for Deoxyribose Nucleic Acid". (PDF) Nature 171, 737–738 (1953). Accessed 13 Feb 2007.
^ Nature Archives Double Helix of DNA: 50 Years
^ Molecular Configuration in Sodium Thymonucleate. Franklin R. and Gosling R.G.Nature 171, 740–741 (1953)Nature Archives Full Text (PDF)
^ Crystallographic photo of Sodium Thymonucleate, Type B. "Photo 51." M…. 2012-05-25. (原始内容存档于2012-05-25).
^ Molecular Structure of Deoxypentose Nucleic Acids. Wilkins M.H.F., A.R. Stokes A.R. & Wilson, H.R. Nature 171, 738–740 (1953)Nature Archives (PDF)
^ Ev
idence for 2-Chain Helix in Crystalline Structure of Sodium Deoxyribonucleate. Franklin R. and Gosling R.G. Nature 172, 156–157 (1953)Nature Archives, full text (PDF)
^ The Nobel Prize in Physiology or Medicine 1962 Nobelprize .org Accessed 22 Dec 06
^ Crick, F.H.C. On degenerate templates and the adaptor hypothesis (PDF). 互联网档案馆的存檔,存档日期2008-10-01. genome.wellcome.ac.uk (Lecture, 1955). Accessed 22 Dec 2006
^ Meselson M, Stahl F. The replication of DNA in Escherichia coli. Proc Natl Acad Sci U S A. 1958, 44 (7): 671–82. PMID 16590258.
^ The Nobel Prize in Physiology or Medicine 1968 Nobelprize.org Accessed 22 Dec 06
^ International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. (PDF). Nature. 2001, 409: 860−921.
^ Venter, JC; 等. The sequence of the human genome. (PDF). Science. 2001, 291: 1304−1351.
延伸閱讀
维基文库中相关的原始文献:
(中文) 林正焜、洪火樹《認識DNA:下一波的醫療革命》。商周出版,2005年。ISBN 978-986-124-428-0
(中文) Karl Drlica。周業仁譯。《DNA的14堂課》(Understanding DNA and Gene Cloning)。天下文化,2002年。ISBN 978-986-417-077-7
(中文) James D. Watson。陳正萱、張項譯。《雙螺旋─DNA結構發現者的青春告白》(The Double Helix)。時報出版,1998年。ISBN 978-957-13-2617-7
(英文) Clayton, Julie. (Ed.). 50 Years of DNA, Palgrave MacMillan Press, 2003. ISBN 978-1-4039-1479-8
(英文) Judson, Horace Freeland. The Eighth Day of Creation: Makers of the Revolution in Biology, Cold Spring Harbor Laboratory Press, 1996. ISBN 978-0-87969-478-4
(英文) Olby, Robert. The Path to The Double Helix: Discovery of DNA, first published in October 1974 by MacMillan, with foreword by Francis Crick; ISBN 978-0-486-68117-7; the definitive DNA textbook, revised in 1994, with a 9 page postscript.
(英文) Ridley, Matt. Francis Crick: Discoverer of the Genetic Code (Eminent Lives) HarperCollins Publishers; 192 pp, ISBN 978-0-06-082333-7 2006
(英文) Rose, Steven. The Chemistry of Life, Penguin, ISBN 978-0-14-027273-4.
(英文) Watson, James D. and Francis H.C. Crick. A structure for Deoxyribose Nucleic Acid (PDF). Nature 171, 737–738, 25 April 1953.
(英文) Watson, James D. DNA: The Secret of Life ISBN 978-0-375-41546-3.
(英文) Watson, James D. The Double Helix: A Personal Account of the Discovery of the Structure of DNA (Norton Critical Editions). ISBN 978-0-393-95075-5
(英文) Watson, James D. "Avoid boring people and other lessons from a life in science" New York: Random House. ISBN 978-0-375-421844
(英文) Calladine, Chris R.; Drew, Horace R.; Luisi, Ben F. and Travers, Andrew A. Understanding DNA, Elsevier Academic Press, 2003. ISBN 978-0-12-155089-9
外部連結
维基共享资源中相关的多媒体资源:脱氧核糖核酸 |
(中文) 核酸 - 生物化學教學網頁
(中文) 畫說DNA - DNA from the beginning中文版,以動畫介紹DNA
(英文) DNA Interactive - Flash互動式介紹
(英文) DNA from the beginning
(英文) The Register of Francis Crick Personal Papers - 佛朗西斯·克里克的文章
(英文) Double Helix 1953–2003 英國國家生物技術教育中心
(英文) Double helix: 50 years of DNA, Nature
(英文) Rosalind Franklin's contributions to the study of DNA
(英文) U.S. National DNA Day - DNA日
(英文) Genetic Education Modules for Teachers - DNA from the Beginning學習指導
(英文) Listen to Francis Crick and James Watson talking on the BBC in 1962, 1972, and 1974
(英文) DNA under electron microscope
(英文) DNA Articles - 論文與訊息收集
(英文) DNA coiling to form chromosomes
(英文) DISPLAR: DNA binding site prediction on protein
(英文) Dolan DNA Learning Center
(英文) Olby, R. (2003) "Quiet debut for the double helix" Nature 421 (January 23): 402–405.
(英文) Basic animated guide to DNA cloning
(英文) DNA the Double Helix Game - 諾貝爾獎官方網站
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||
|


